зҙўеј•зӣ®зҡ„
зҙўеј•зҡ„зӣ®зҡ„еңЁдәҺжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢеҸҜд»Ҙзұ»жҜ”еӯ—е…ёпјҢеҰӮжһңиҰҒжҹҘвҖңmysqlвҖқиҝҷдёӘеҚ•иҜҚпјҢжҲ‘们иӮҜе®ҡйңҖиҰҒе®ҡдҪҚеҲ°mеӯ—жҜҚпјҢ然еҗҺд»ҺдёӢеҫҖдёӢжүҫеҲ°yеӯ—жҜҚпјҢеҶҚжүҫеҲ°еү©дёӢзҡ„sqlгҖӮеҰӮжһңжІЎжңүзҙўеј•пјҢйӮЈд№ҲдҪ еҸҜиғҪйңҖиҰҒжҠҠжүҖжңүеҚ•иҜҚзңӢдёҖйҒҚжүҚиғҪжүҫеҲ°дҪ жғіиҰҒзҡ„пјҢеҰӮжһңжҲ‘жғіжүҫеҲ°mејҖеӨҙзҡ„еҚ•иҜҚе‘ўпјҹжҲ–иҖ…wејҖеӨҙзҡ„еҚ•иҜҚе‘ўпјҹжҳҜдёҚжҳҜи§үеҫ—еҰӮжһңжІЎжңүзҙўеј•пјҢиҝҷдёӘдәӢжғ…ж №жң¬ж— жі•е®ҢжҲҗпјҹ
зҙўеј•еҺҹзҗҶ
йҷӨдәҶиҜҚе…ёпјҢз”ҹжҙ»дёӯйҡҸеӨ„еҸҜи§Ғзҙўеј•зҡ„дҫӢеӯҗпјҢеҰӮзҒ«иҪҰз«ҷзҡ„иҪҰж¬ЎиЎЁгҖҒеӣҫд№Ұзҡ„зӣ®еҪ•зӯүгҖӮе®ғ们зҡ„еҺҹзҗҶйғҪжҳҜдёҖж ·зҡ„пјҢйҖҡиҝҮдёҚж–ӯзҡ„зј©е°ҸжғіиҰҒиҺ·еҫ—ж•°жҚ®зҡ„иҢғеӣҙжқҘзӯӣйҖүеҮәжңҖз»ҲжғіиҰҒзҡ„з»“жһңпјҢеҗҢж—¶жҠҠйҡҸжңәзҡ„дәӢ件еҸҳжҲҗйЎәеәҸзҡ„дәӢ件пјҢд№ҹе°ұжҳҜжҲ‘们жҖ»жҳҜйҖҡиҝҮеҗҢдёҖз§ҚжҹҘжүҫж–№ејҸжқҘй”Ғе®ҡж•°жҚ®гҖӮ
ж•°жҚ®еә“д№ҹжҳҜдёҖж ·пјҢдҪҶжҳҫ然иҰҒеӨҚжқӮи®ёеӨҡпјҢеӣ дёәдёҚд»…йқўдёҙзқҖзӯүеҖјжҹҘиҜўпјҢиҝҳжңүиҢғеӣҙжҹҘиҜў(>гҖҒ<гҖҒbetweenгҖҒin)гҖҒжЁЎзіҠжҹҘиҜў(like)гҖҒ并йӣҶжҹҘиҜў(or)зӯүзӯүгҖӮж•°жҚ®еә“еә”иҜҘйҖүжӢ©жҖҺд№Ҳж ·зҡ„ж–№ејҸжқҘеә”еҜ№жүҖжңүзҡ„й—®йўҳе‘ўпјҹжҲ‘们еӣһжғіеӯ—е…ёзҡ„дҫӢеӯҗпјҢиғҪдёҚиғҪжҠҠж•°жҚ®еҲҶжҲҗж®өпјҢ然еҗҺеҲҶж®өжҹҘиҜўе‘ўпјҹжңҖз®ҖеҚ•зҡ„еҰӮжһң1000жқЎж•°жҚ®пјҢ1еҲ°100еҲҶжҲҗ第дёҖж®өпјҢ101еҲ°200еҲҶжҲҗ第дәҢж®өпјҢ201еҲ°300еҲҶжҲҗ第дёүж®өвҖҰвҖҰиҝҷж ·жҹҘ第250жқЎж•°жҚ®пјҢеҸӘиҰҒжүҫ第дёүж®өе°ұеҸҜд»ҘдәҶпјҢдёҖдёӢеӯҗеҺ»йҷӨдәҶ90%зҡ„ж— ж•Ҳж•°жҚ®гҖӮдҪҶеҰӮжһңжҳҜ1еҚғдёҮзҡ„и®°еҪ•е‘ўпјҢеҲҶжҲҗеҮ ж®өжҜ”иҫғеҘҪпјҹзЁҚжңүз®—жі•еҹәзЎҖзҡ„еҗҢеӯҰдјҡжғіеҲ°жҗңзҙўж ‘пјҢе…¶е№іеқҮеӨҚжқӮеәҰжҳҜlgNпјҢе…·жңүдёҚй”ҷзҡ„жҹҘиҜўжҖ§иғҪгҖӮдҪҶиҝҷйҮҢжҲ‘们еҝҪз•ҘдәҶдёҖдёӘе…ій”®зҡ„й—®йўҳпјҢеӨҚжқӮеәҰжЁЎеһӢжҳҜеҹәдәҺжҜҸж¬ЎзӣёеҗҢзҡ„ж“ҚдҪңжҲҗжң¬жқҘиҖғиҷ‘зҡ„пјҢж•°жҚ®еә“е®һзҺ°жҜ”иҫғеӨҚжқӮпјҢж•°жҚ®дҝқеӯҳеңЁзЈҒзӣҳдёҠпјҢиҖҢдёәдәҶжҸҗй«ҳжҖ§иғҪпјҢжҜҸж¬ЎеҸҲеҸҜд»ҘжҠҠйғЁеҲҶж•°жҚ®иҜ»е…ҘеҶ…еӯҳжқҘи®Ўз®—пјҢеӣ дёәжҲ‘们зҹҘйҒ“и®ҝй—®зЈҒзӣҳзҡ„жҲҗжң¬еӨ§жҰӮжҳҜи®ҝй—®еҶ…еӯҳзҡ„еҚҒдёҮеҖҚе·ҰеҸіпјҢжүҖд»Ҙз®ҖеҚ•зҡ„жҗңзҙўж ‘йҡҫд»Ҙж»Ўи¶іеӨҚжқӮзҡ„еә”з”ЁеңәжҷҜгҖӮ
зЈҒзӣҳIOдёҺйў„иҜ»
еүҚйқўжҸҗеҲ°дәҶи®ҝй—®зЈҒзӣҳпјҢйӮЈд№ҲиҝҷйҮҢе…Ҳз®ҖеҚ•д»Ӣз»ҚдёҖдёӢзЈҒзӣҳIOе’Ңйў„иҜ»пјҢзЈҒзӣҳиҜ»еҸ–ж•°жҚ®йқ зҡ„жҳҜжңәжў°иҝҗеҠЁпјҢжҜҸж¬ЎиҜ»еҸ–ж•°жҚ®иҠұиҙ№зҡ„ж—¶й—ҙеҸҜд»ҘеҲҶдёәеҜ»йҒ“ж—¶й—ҙгҖҒж—ӢиҪ¬е»¶иҝҹгҖҒдј иҫ“ж—¶й—ҙдёүдёӘйғЁеҲҶпјҢеҜ»йҒ“ж—¶й—ҙжҢҮзҡ„жҳҜзЈҒиҮӮ移еҠЁеҲ°жҢҮе®ҡзЈҒйҒ“жүҖйңҖиҰҒзҡ„ж—¶й—ҙпјҢдё»жөҒзЈҒзӣҳдёҖиҲ¬еңЁ5msд»ҘдёӢпјӣж—ӢиҪ¬е»¶иҝҹе°ұжҳҜжҲ‘们з»Ҹеёёеҗ¬иҜҙзҡ„зЈҒзӣҳиҪ¬йҖҹпјҢжҜ”еҰӮдёҖдёӘзЈҒзӣҳ7200иҪ¬пјҢиЎЁзӨәжҜҸеҲҶй’ҹиғҪиҪ¬7200ж¬ЎпјҢд№ҹе°ұжҳҜиҜҙ1з§’й’ҹиғҪиҪ¬120ж¬ЎпјҢж—ӢиҪ¬е»¶иҝҹе°ұжҳҜ1/120/2 = 4.17msпјӣдј иҫ“ж—¶й—ҙжҢҮзҡ„жҳҜд»ҺзЈҒзӣҳиҜ»еҮәжҲ–е°Ҷж•°жҚ®еҶҷе…ҘзЈҒзӣҳзҡ„ж—¶й—ҙпјҢдёҖиҲ¬еңЁйӣ¶зӮ№еҮ жҜ«з§’пјҢзӣёеҜ№дәҺеүҚдёӨдёӘж—¶й—ҙеҸҜд»ҘеҝҪз•ҘдёҚи®ЎгҖӮйӮЈд№Ҳи®ҝй—®дёҖж¬ЎзЈҒзӣҳзҡ„ж—¶й—ҙпјҢеҚідёҖж¬ЎзЈҒзӣҳIOзҡ„ж—¶й—ҙзәҰзӯүдәҺ5+4.17 = 9msе·ҰеҸіпјҢеҗ¬иө·жқҘиҝҳжҢәдёҚй”ҷзҡ„пјҢдҪҶиҰҒзҹҘйҒ“дёҖеҸ°500 -MIPSзҡ„жңәеҷЁжҜҸз§’еҸҜд»Ҙжү§иЎҢ5дәҝжқЎжҢҮд»ӨпјҢеӣ дёәжҢҮд»Өдҫқйқ зҡ„жҳҜз”өзҡ„жҖ§иҙЁпјҢжҚўеҸҘиҜқиҜҙжү§иЎҢдёҖж¬ЎIOзҡ„ж—¶й—ҙеҸҜд»Ҙжү§иЎҢ40дёҮжқЎжҢҮд»ӨпјҢж•°жҚ®еә“еҠЁиҫ„еҚҒдёҮзҷҫдёҮд№ғиҮіеҚғдёҮзә§ж•°жҚ®пјҢжҜҸж¬Ў9жҜ«з§’зҡ„ж—¶й—ҙпјҢжҳҫ然жҳҜдёӘзҒҫйҡҫгҖӮдёӢеӣҫжҳҜи®Ўз®—жңә硬件延иҝҹзҡ„еҜ№жҜ”еӣҫпјҢдҫӣеӨ§е®¶еҸӮиҖғпјҡ

иҖғиҷ‘еҲ°зЈҒзӣҳIOжҳҜйқһеёёй«ҳжҳӮзҡ„ж“ҚдҪңпјҢи®Ўз®—жңәж“ҚдҪңзі»з»ҹеҒҡдәҶдёҖдәӣдјҳеҢ–пјҢеҪ“дёҖж¬ЎIOж—¶пјҢдёҚе…үжҠҠеҪ“еүҚзЈҒзӣҳең°еқҖзҡ„ж•°жҚ®пјҢиҖҢжҳҜжҠҠзӣёйӮ»зҡ„ж•°жҚ®д№ҹйғҪиҜ»еҸ–еҲ°еҶ…еӯҳзј“еҶІеҢәеҶ…пјҢеӣ дёәеұҖйғЁйў„иҜ»жҖ§еҺҹзҗҶе‘ҠиҜүжҲ‘们пјҢеҪ“и®Ўз®—жңәи®ҝй—®дёҖдёӘең°еқҖзҡ„ж•°жҚ®зҡ„ж—¶еҖҷпјҢдёҺе…¶зӣёйӮ»зҡ„ж•°жҚ®д№ҹдјҡеҫҲеҝ«иў«и®ҝй—®еҲ°гҖӮжҜҸдёҖж¬ЎIOиҜ»еҸ–зҡ„ж•°жҚ®жҲ‘们称д№ӢдёәдёҖйЎө(page)гҖӮе…·дҪ“дёҖйЎөжңүеӨҡеӨ§ж•°жҚ®и·ҹж“ҚдҪңзі»з»ҹжңүе…іпјҢдёҖиҲ¬дёә4kжҲ–8kпјҢд№ҹе°ұжҳҜжҲ‘们иҜ»еҸ–дёҖйЎөеҶ…зҡ„ж•°жҚ®ж—¶еҖҷпјҢе®һйҷ…дёҠжүҚеҸ‘з”ҹдәҶдёҖж¬ЎIOпјҢиҝҷдёӘзҗҶи®әеҜ№дәҺзҙўеј•зҡ„ж•°жҚ®з»“жһ„и®ҫи®Ўйқһеёёжңүеё®еҠ©гҖӮ
зҙўеј•зҡ„ж•°жҚ®з»“жһ„
еүҚйқўи®ІдәҶз”ҹжҙ»дёӯзҙўеј•зҡ„дҫӢеӯҗпјҢзҙўеј•зҡ„еҹәжң¬еҺҹзҗҶпјҢж•°жҚ®еә“зҡ„еӨҚжқӮжҖ§пјҢеҸҲи®ІдәҶж“ҚдҪңзі»з»ҹзҡ„зӣёе…ізҹҘиҜҶпјҢзӣ®зҡ„е°ұжҳҜи®©еӨ§е®¶дәҶи§ЈпјҢд»»дҪ•дёҖз§Қж•°жҚ®з»“жһ„йғҪдёҚжҳҜеҮӯз©әдә§з”ҹзҡ„пјҢдёҖе®ҡдјҡжңүе®ғзҡ„иғҢжҷҜе’ҢдҪҝз”ЁеңәжҷҜпјҢжҲ‘们зҺ°еңЁжҖ»з»“дёҖдёӢпјҢжҲ‘们йңҖиҰҒиҝҷз§Қж•°жҚ®з»“жһ„иғҪеӨҹеҒҡдәӣд»Җд№ҲпјҢе…¶е®һеҫҲз®ҖеҚ•пјҢйӮЈе°ұжҳҜпјҡжҜҸж¬ЎжҹҘжүҫж•°жҚ®ж—¶жҠҠзЈҒзӣҳIOж¬Ўж•°жҺ§еҲ¶еңЁдёҖдёӘеҫҲе°Ҹзҡ„ж•°йҮҸзә§пјҢжңҖеҘҪжҳҜеёёж•°ж•°йҮҸзә§гҖӮйӮЈд№ҲжҲ‘们е°ұжғіеҲ°еҰӮжһңдёҖдёӘй«ҳеәҰеҸҜжҺ§зҡ„еӨҡи·Ҝжҗңзҙўж ‘жҳҜеҗҰиғҪж»Ўи¶ійңҖжұӮе‘ўпјҹе°ұиҝҷж ·пјҢb+ж ‘еә”иҝҗиҖҢз”ҹгҖӮ
b+ж ‘иҜҰи§Ј
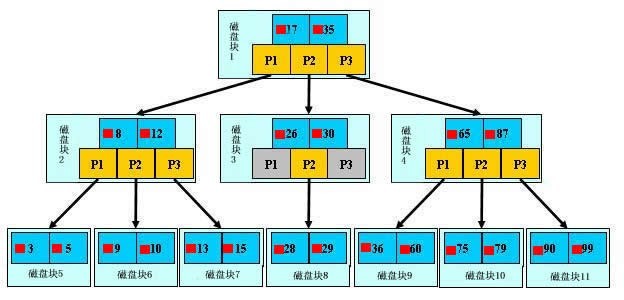
еҰӮдёҠеӣҫпјҢжҳҜдёҖйў—b+ж ‘пјҢиҝҷйҮҢеҸӘиҜҙдёҖдәӣйҮҚзӮ№пјҢжө…и“қиүІзҡ„еқ—жҲ‘们称д№ӢдёәдёҖдёӘзЈҒзӣҳеқ—пјҢеҸҜд»ҘзңӢеҲ°жҜҸдёӘзЈҒзӣҳеқ—еҢ…еҗ«еҮ дёӘж•°жҚ®йЎ№(ж·ұи“қиүІжүҖзӨә)е’ҢжҢҮй’Ҳ(й»„иүІжүҖзӨә)пјҢеҰӮзЈҒзӣҳеқ—1еҢ…еҗ«ж•°жҚ®йЎ№17е’Ң35пјҢеҢ…еҗ«жҢҮй’ҲP1гҖҒP2гҖҒP3пјҢP1иЎЁзӨәе°ҸдәҺ17зҡ„зЈҒзӣҳеқ—пјҢP2иЎЁзӨәеңЁ17е’Ң35д№Ӣй—ҙзҡ„зЈҒзӣҳеқ—пјҢP3иЎЁзӨәеӨ§дәҺ35зҡ„зЈҒзӣҳеқ—гҖӮзңҹе®һзҡ„ж•°жҚ®еӯҳеңЁдәҺеҸ¶еӯҗиҠӮзӮ№еҚі3гҖҒ5гҖҒ9гҖҒ10гҖҒ13гҖҒ15гҖҒ28гҖҒ29гҖҒ36гҖҒ60гҖҒ75гҖҒ79гҖҒ90гҖҒ99гҖӮйқһеҸ¶еӯҗиҠӮзӮ№еҸӘдёҚеӯҳеӮЁзңҹе®һзҡ„ж•°жҚ®пјҢеҸӘеӯҳеӮЁжҢҮеј•жҗңзҙўж–№еҗ‘зҡ„ж•°жҚ®йЎ№пјҢеҰӮ17гҖҒ35并дёҚзңҹе®һеӯҳеңЁдәҺж•°жҚ®иЎЁдёӯгҖӮ
b+ж ‘зҡ„жҹҘжүҫиҝҮзЁӢ
еҰӮеӣҫжүҖзӨәпјҢеҰӮжһңиҰҒжҹҘжүҫж•°жҚ®йЎ№29пјҢйӮЈд№ҲйҰ–е…ҲдјҡжҠҠзЈҒзӣҳеқ—1з”ұзЈҒзӣҳеҠ иҪҪеҲ°еҶ…еӯҳпјҢжӯӨж—¶еҸ‘з”ҹдёҖж¬ЎIOпјҢеңЁеҶ…еӯҳдёӯз”ЁдәҢеҲҶжҹҘжүҫзЎ®е®ҡ29еңЁ17е’Ң35д№Ӣй—ҙпјҢй”Ғе®ҡзЈҒзӣҳеқ—1зҡ„P2жҢҮй’ҲпјҢеҶ…еӯҳж—¶й—ҙеӣ дёәйқһеёёзҹӯ(зӣёжҜ”зЈҒзӣҳзҡ„IO)еҸҜд»ҘеҝҪз•ҘдёҚи®ЎпјҢйҖҡиҝҮзЈҒзӣҳеқ—1зҡ„P2жҢҮй’Ҳзҡ„зЈҒзӣҳең°еқҖжҠҠзЈҒзӣҳеқ—3з”ұзЈҒзӣҳеҠ иҪҪеҲ°еҶ…еӯҳпјҢеҸ‘з”ҹ第дәҢж¬ЎIOпјҢ29еңЁ26е’Ң30д№Ӣй—ҙпјҢй”Ғе®ҡзЈҒзӣҳеқ—3зҡ„P2жҢҮй’ҲпјҢйҖҡиҝҮжҢҮй’ҲеҠ иҪҪзЈҒзӣҳеқ—8еҲ°еҶ…еӯҳпјҢеҸ‘з”ҹ第дёүж¬ЎIOпјҢеҗҢж—¶еҶ…еӯҳдёӯеҒҡдәҢеҲҶжҹҘжүҫжүҫеҲ°29пјҢз»“жқҹжҹҘиҜўпјҢжҖ»и®Ўдёүж¬ЎIOгҖӮзңҹе®һзҡ„жғ…еҶөжҳҜпјҢ3еұӮзҡ„b+ж ‘еҸҜд»ҘиЎЁзӨәдёҠзҷҫдёҮзҡ„ж•°жҚ®пјҢеҰӮжһңдёҠзҷҫдёҮзҡ„ж•°жҚ®жҹҘжүҫеҸӘйңҖиҰҒдёүж¬ЎIOпјҢжҖ§иғҪжҸҗй«ҳе°ҶжҳҜе·ЁеӨ§зҡ„пјҢеҰӮжһңжІЎжңүзҙўеј•пјҢжҜҸдёӘж•°жҚ®йЎ№йғҪиҰҒеҸ‘з”ҹдёҖж¬ЎIOпјҢйӮЈд№ҲжҖ»е…ұйңҖиҰҒзҷҫдёҮж¬Ўзҡ„IOпјҢжҳҫ然жҲҗжң¬йқһеёёйқһеёёй«ҳгҖӮ
b+ж ‘жҖ§иҙЁ
1.йҖҡиҝҮдёҠйқўзҡ„еҲҶжһҗпјҢжҲ‘们зҹҘйҒ“IOж¬Ўж•°еҸ–еҶідәҺb+ж•°зҡ„й«ҳеәҰhпјҢеҒҮи®ҫеҪ“еүҚж•°жҚ®иЎЁзҡ„ж•°жҚ®дёәNпјҢжҜҸдёӘзЈҒзӣҳеқ—зҡ„ж•°жҚ®йЎ№зҡ„ж•°йҮҸжҳҜmпјҢеҲҷжңүh=гҸ’(m+1)NпјҢеҪ“ж•°жҚ®йҮҸNдёҖе®ҡзҡ„жғ…еҶөдёӢпјҢmи¶ҠеӨ§пјҢhи¶Ҡе°ҸпјӣиҖҢm = зЈҒзӣҳеқ—зҡ„еӨ§е°Ҹ / ж•°жҚ®йЎ№зҡ„еӨ§е°ҸпјҢзЈҒзӣҳеқ—зҡ„еӨ§е°Ҹд№ҹе°ұжҳҜдёҖдёӘж•°жҚ®йЎөзҡ„еӨ§е°ҸпјҢжҳҜеӣәе®ҡзҡ„пјҢеҰӮжһңж•°жҚ®йЎ№еҚ зҡ„з©әй—ҙи¶Ҡе°ҸпјҢж•°жҚ®йЎ№зҡ„ж•°йҮҸи¶ҠеӨҡпјҢж ‘зҡ„й«ҳеәҰи¶ҠдҪҺгҖӮиҝҷе°ұжҳҜдёәд»Җд№ҲжҜҸдёӘж•°жҚ®йЎ№пјҢеҚізҙўеј•еӯ—ж®өиҰҒе°ҪйҮҸзҡ„е°ҸпјҢжҜ”еҰӮintеҚ 4еӯ—иҠӮпјҢиҰҒжҜ”bigint8еӯ—иҠӮе°‘дёҖеҚҠгҖӮиҝҷд№ҹжҳҜдёәд»Җд№Ҳb+ж ‘иҰҒжұӮжҠҠзңҹе®һзҡ„ж•°жҚ®ж”ҫеҲ°еҸ¶еӯҗиҠӮзӮ№иҖҢдёҚжҳҜеҶ…еұӮиҠӮзӮ№пјҢдёҖж—Ұж”ҫеҲ°еҶ…еұӮиҠӮзӮ№пјҢзЈҒзӣҳеқ—зҡ„ж•°жҚ®йЎ№дјҡеӨ§е№…еәҰдёӢйҷҚпјҢеҜјиҮҙж ‘еўһй«ҳгҖӮеҪ“ж•°жҚ®йЎ№зӯүдәҺ1ж—¶е°ҶдјҡйҖҖеҢ–жҲҗзәҝжҖ§иЎЁгҖӮ
2.еҪ“b+ж ‘зҡ„ж•°жҚ®йЎ№жҳҜеӨҚеҗҲзҡ„ж•°жҚ®з»“жһ„пјҢжҜ”еҰӮ(name,age,sex)зҡ„ж—¶еҖҷпјҢb+ж•°жҳҜжҢүз…§д»Һе·ҰеҲ°еҸізҡ„йЎәеәҸжқҘе»әз«Ӣжҗңзҙўж ‘зҡ„пјҢжҜ”еҰӮеҪ“(еј дёү,20,F)иҝҷж ·зҡ„ж•°жҚ®жқҘжЈҖзҙўзҡ„ж—¶еҖҷпјҢb+ж ‘дјҡдјҳе…ҲжҜ”иҫғnameжқҘзЎ®е®ҡдёӢдёҖжӯҘзҡ„жүҖжҗңж–№еҗ‘пјҢеҰӮжһңnameзӣёеҗҢеҶҚдҫқж¬ЎжҜ”иҫғageе’ҢsexпјҢжңҖеҗҺеҫ—еҲ°жЈҖзҙўзҡ„ж•°жҚ®пјӣдҪҶеҪ“(20,F)иҝҷж ·зҡ„жІЎжңүnameзҡ„ж•°жҚ®жқҘзҡ„ж—¶еҖҷпјҢb+ж ‘е°ұдёҚзҹҘйҒ“дёӢдёҖжӯҘиҜҘжҹҘе“ӘдёӘиҠӮзӮ№пјҢеӣ дёәе»әз«Ӣжҗңзҙўж ‘зҡ„ж—¶еҖҷnameе°ұжҳҜ第дёҖдёӘжҜ”иҫғеӣ еӯҗпјҢеҝ…йЎ»иҰҒе…Ҳж №жҚ®nameжқҘжҗңзҙўжүҚиғҪзҹҘйҒ“дёӢдёҖжӯҘеҺ»е“ӘйҮҢжҹҘиҜўгҖӮжҜ”еҰӮеҪ“(еј дёү,F)иҝҷж ·зҡ„ж•°жҚ®жқҘжЈҖзҙўж—¶пјҢb+ж ‘еҸҜд»Ҙз”ЁnameжқҘжҢҮе®ҡжҗңзҙўж–№еҗ‘пјҢдҪҶдёӢдёҖдёӘеӯ—ж®өageзҡ„зјәеӨұпјҢжүҖд»ҘеҸӘиғҪжҠҠеҗҚеӯ—зӯүдәҺеј дёүзҡ„ж•°жҚ®йғҪжүҫеҲ°пјҢ然еҗҺеҶҚеҢ№й…ҚжҖ§еҲ«жҳҜFзҡ„ж•°жҚ®дәҶпјҢ иҝҷдёӘжҳҜйқһеёёйҮҚиҰҒзҡ„жҖ§иҙЁпјҢеҚізҙўеј•зҡ„жңҖе·ҰеҢ№й…Қзү№жҖ§гҖӮ
ж…ўжҹҘиҜўдјҳеҢ–
е…ідәҺMySQLзҙўеј•еҺҹзҗҶжҳҜжҜ”иҫғжһҜзҮҘзҡ„дёңиҘҝпјҢеӨ§е®¶еҸӘйңҖиҰҒжңүдёҖдёӘж„ҹжҖ§зҡ„и®ӨиҜҶпјҢ并дёҚйңҖиҰҒзҗҶи§Јеҫ—йқһеёёйҖҸеҪ»е’Ңж·ұе…ҘгҖӮжҲ‘们еӣһеӨҙжқҘзңӢзңӢдёҖејҖе§ӢжҲ‘们иҜҙзҡ„ж…ўжҹҘиҜўпјҢдәҶи§Је®Ңзҙўеј•еҺҹзҗҶд№ӢеҗҺпјҢеӨ§е®¶жҳҜдёҚжҳҜжңүд»Җд№Ҳжғіжі•е‘ўпјҹе…ҲжҖ»з»“дёҖдёӢзҙўеј•зҡ„еҮ еӨ§еҹәжң¬еҺҹеҲҷ
е»әзҙўеј•зҡ„еҮ еӨ§еҺҹеҲҷ
1.жңҖе·ҰеүҚзјҖеҢ№й…ҚеҺҹеҲҷпјҢйқһеёёйҮҚиҰҒзҡ„еҺҹеҲҷпјҢmysqlдјҡдёҖзӣҙеҗ‘еҸіеҢ№й…ҚзӣҙеҲ°йҒҮеҲ°иҢғеӣҙжҹҘиҜў(>гҖҒ<гҖҒbetweenгҖҒlike)е°ұеҒңжӯўеҢ№й…ҚпјҢжҜ”еҰӮa = 1 and b = 2 and c > 3 and d = 4 еҰӮжһңе»әз«Ӣ(a,b,c,d)йЎәеәҸзҡ„зҙўеј•пјҢdжҳҜз”ЁдёҚеҲ°зҙўеј•зҡ„пјҢеҰӮжһңе»әз«Ӣ(a,b,d,c)зҡ„зҙўеј•еҲҷйғҪеҸҜд»Ҙз”ЁеҲ°пјҢa,b,dзҡ„йЎәеәҸеҸҜд»Ҙд»»ж„Ҹи°ғж•ҙгҖӮ
2.=е’ҢinеҸҜд»Ҙд№ұеәҸпјҢжҜ”еҰӮa = 1 and b = 2 and c = 3 е»әз«Ӣ(a,b,c)зҙўеј•еҸҜд»Ҙд»»ж„ҸйЎәеәҸпјҢmysqlзҡ„жҹҘиҜўдјҳеҢ–еҷЁдјҡеё®дҪ дјҳеҢ–жҲҗзҙўеј•еҸҜд»ҘиҜҶеҲ«зҡ„еҪўејҸ
3.е°ҪйҮҸйҖүжӢ©еҢәеҲҶеәҰй«ҳзҡ„еҲ—дҪңдёәзҙўеј•,еҢәеҲҶеәҰзҡ„е…¬ејҸжҳҜcount(distinct col)/count(*)пјҢиЎЁзӨәеӯ—ж®өдёҚйҮҚеӨҚзҡ„жҜ”дҫӢпјҢжҜ”дҫӢи¶ҠеӨ§жҲ‘们жү«жҸҸзҡ„и®°еҪ•ж•°и¶Ҡе°‘пјҢе”ҜдёҖй”®зҡ„еҢәеҲҶеәҰжҳҜ1пјҢиҖҢдёҖдәӣзҠ¶жҖҒгҖҒжҖ§еҲ«еӯ—ж®өеҸҜиғҪеңЁеӨ§ж•°жҚ®йқўеүҚеҢәеҲҶеәҰе°ұжҳҜ0пјҢйӮЈеҸҜиғҪжңүдәәдјҡй—®пјҢиҝҷдёӘжҜ”дҫӢжңүд»Җд№Ҳз»ҸйӘҢеҖјеҗ—пјҹдҪҝз”ЁеңәжҷҜдёҚеҗҢпјҢиҝҷдёӘеҖјд№ҹеҫҲйҡҫзЎ®е®ҡпјҢдёҖиҲ¬йңҖиҰҒjoinзҡ„еӯ—ж®өжҲ‘们йғҪиҰҒжұӮжҳҜ0.1д»ҘдёҠпјҢеҚіе№іеқҮ1жқЎжү«жҸҸ10жқЎи®°еҪ•
4.зҙўеј•еҲ—дёҚиғҪеҸӮдёҺи®Ўз®—пјҢдҝқжҢҒеҲ—вҖңе№ІеҮҖвҖқпјҢжҜ”еҰӮfrom_unixtime(create_time) = вҖҷ2014-05-29вҖҷе°ұдёҚиғҪдҪҝз”ЁеҲ°зҙўеј•пјҢеҺҹеӣ еҫҲз®ҖеҚ•пјҢb+ж ‘дёӯеӯҳзҡ„йғҪжҳҜж•°жҚ®иЎЁдёӯзҡ„еӯ—ж®өеҖјпјҢдҪҶиҝӣиЎҢжЈҖзҙўж—¶пјҢйңҖиҰҒжҠҠжүҖжңүе…ғзҙ йғҪеә”з”ЁеҮҪж•°жүҚиғҪжҜ”иҫғпјҢжҳҫ然жҲҗжң¬еӨӘеӨ§гҖӮжүҖд»ҘиҜӯеҸҘеә”иҜҘеҶҷжҲҗcreate_time = unix_timestamp(вҖҷ2014-05-29вҖҷ);
5.е°ҪйҮҸзҡ„жү©еұ•зҙўеј•пјҢдёҚиҰҒж–°е»әзҙўеј•гҖӮжҜ”еҰӮиЎЁдёӯе·Із»Ҹжңүaзҡ„зҙўеј•пјҢзҺ°еңЁиҰҒеҠ (a,b)зҡ„зҙўеј•пјҢйӮЈд№ҲеҸӘйңҖиҰҒдҝ®ж”№еҺҹжқҘзҡ„зҙўеј•еҚіеҸҜ
дёҖжқЎз®ҖеҚ•sqlзҡ„жҹҘиҜўдјҳеҢ–
select count(*) from task where status=2 and operator_id=20839 and operate_time>1371169729 and operate_time<1371174603 and type=2;
ж №жҚ®жңҖе·ҰеҢ№й…ҚеҺҹеҲҷпјҢиҜҘsqlиҜӯеҸҘзҡ„зҙўеј•еә”иҜҘжҳҜstatusгҖҒoperator_idгҖҒtypeгҖҒoperate_timeзҡ„иҒ”еҗҲзҙўеј•пјӣе…¶дёӯstatusгҖҒoperator_idгҖҒtypeзҡ„йЎәеәҸеҸҜд»Ҙйў еҖ’;
жҜ”еҰӮиҝҳжңүеҰӮдёӢжҹҘиҜў
select * from task where status = 0 and type = 12 limit 10;
select count(*) from task where status = 0 ;
йӮЈд№Ҳзҙўеј•е»әз«ӢжҲҗ(status,type,operator_id,operate_time)е°ұжҳҜйқһеёёжӯЈзЎ®зҡ„пјҢеӣ дёәеҸҜд»ҘиҰҶзӣ–еҲ°жүҖжңүжғ…еҶөгҖӮиҝҷдёӘе°ұжҳҜеҲ©з”ЁдәҶзҙўеј•зҡ„жңҖе·ҰеҢ№й…Қзҡ„еҺҹеҲҷ
жҹҘиҜўдјҳеҢ–зҘһеҷЁ – explainе‘Ҫд»Ө
е…ідәҺexplainе‘Ҫд»ӨзӣёдҝЎеӨ§е®¶е№¶дёҚйҷҢз”ҹпјҢе…·дҪ“з”Ёжі•е’Ңеӯ—ж®өеҗ«д№үеҸҜд»ҘеҸӮиҖғе®ҳзҪ‘explain-outputпјҢиҝҷйҮҢйңҖиҰҒејәи°ғrowsжҳҜж ёеҝғжҢҮж ҮпјҢз»қеӨ§йғЁеҲҶrowsе°Ҹзҡ„иҜӯеҸҘжү§иЎҢдёҖе®ҡеҫҲеҝ«(жңүдҫӢеӨ–пјҢдёӢйқўдјҡи®ІеҲ°)гҖӮжүҖд»ҘдјҳеҢ–иҜӯеҸҘеҹәжң¬дёҠйғҪжҳҜеңЁдјҳеҢ–rowsгҖӮ
ж…ўжҹҘиҜўдјҳеҢ–еҹәжң¬жӯҘйӘӨ
0.е…ҲиҝҗиЎҢзңӢзңӢжҳҜеҗҰзңҹзҡ„еҫҲж…ўпјҢжіЁж„Ҹи®ҫзҪ®SQL_NO_CACHE
1.whereжқЎд»¶еҚ•иЎЁжҹҘпјҢй”Ғе®ҡжңҖе°Ҹиҝ”еӣһи®°еҪ•иЎЁгҖӮиҝҷеҸҘиҜқзҡ„ж„ҸжҖқжҳҜжҠҠжҹҘиҜўиҜӯеҸҘзҡ„whereйғҪеә”з”ЁеҲ°иЎЁдёӯиҝ”еӣһзҡ„и®°еҪ•ж•°жңҖе°Ҹзҡ„иЎЁејҖе§ӢжҹҘиө·пјҢеҚ•иЎЁжҜҸдёӘеӯ—ж®өеҲҶеҲ«жҹҘиҜўпјҢзңӢе“ӘдёӘеӯ—ж®өзҡ„еҢәеҲҶеәҰжңҖй«ҳ
2.explainжҹҘзңӢжү§иЎҢи®ЎеҲ’пјҢжҳҜеҗҰдёҺ1йў„жңҹдёҖиҮҙ(д»Һй”Ғе®ҡи®°еҪ•иҫғе°‘зҡ„иЎЁејҖе§ӢжҹҘиҜў)
3.order by limit еҪўејҸзҡ„sqlиҜӯеҸҘи®©жҺ’еәҸзҡ„иЎЁдјҳе…ҲжҹҘ
4.дәҶи§ЈдёҡеҠЎж–№дҪҝз”ЁеңәжҷҜ
5.еҠ зҙўеј•ж—¶еҸӮз…§е»әзҙўеј•зҡ„еҮ еӨ§еҺҹеҲҷ
6.и§ӮеҜҹз»“жһңпјҢдёҚз¬ҰеҗҲйў„жңҹ继з»ӯд»Һ0еҲҶжһҗ
еҒҡдёӘеҸӢй“ҫеҗ§