еӨ§зәҰеңЁдёӨе№ҙеүҚпјҢжҲ‘еҶҷдәҶдёҖзҜҮе…ідәҺMySQLзҙўеј•зҡ„ж–Үз« гҖӮжңҖиҝ‘жңүеҗҢеӯҰеңЁж–Үз« зҡ„иҜ„и®әдёӯеҜ№ж–Үз« зҡ„еҶ…е®№жҸҗеҮәиҙЁз–‘пјҢиҙЁз–‘дё»иҰҒйӣҶдёӯеңЁиҒ”еҗҲзҙўеј•зҡ„дҪҝз”Ёж–№ејҸдёҠгҖӮеңЁйӮЈзҜҮж–Үз« дёӯпјҢжҲ‘иҜҙжҳҺиҒ”еҗҲзҙўеј•жҳҜе°Ҷеҗ„дёӘзҙўеј•еӯ—ж®өеҒҡеӯ—з¬ҰдёІиҝһжҺҘеҗҺдҪңдёәkeyпјҢдҪҝз”Ёж—¶е°Ҷж•ҙдҪ“еҒҡеүҚзјҖеҢ№й…ҚгҖӮ
иҖҢиҝҷеҗҚеҗҢеӯҰеңЁиҝҷдёӘйЎөйқўжүҫеҲ°дәҶеҰӮдёӢдёҖеҸҘиҜқпјҡindex condition pushdown is usually useful with multi-column indexes: the first component(s) is what index access is done for, the subsequent have columns that we read and check conditions onгҖӮд»ҺиҖҢи®ӨдёәиҒ”еҗҲзҙўеј•зҡ„дҪҝз”Ёж–№ејҸдёҺж–ҮдёӯдёҚз¬ҰгҖӮ
е®һйҷ…дёҠпјҢиҝҷдёӘйЎөйқўжүҖи®Іиҝ°зҡ„жҳҜеңЁMariaDB 5.3.3пјҲMySQLжҳҜеңЁ5.6пјүејҖе§Ӣеј•е…Ҙзҡ„дёҖз§ҚеҸ«еҒҡIndex Condition PushdownпјҲд»ҘдёӢз®Җз§°ICPпјүзҡ„жҹҘиҜўдјҳеҢ–ж–№ејҸгҖӮз”ұдәҺжң¬иә«дёҚжҳҜдёҖдёӘеұӮйқўзҡ„дёңиҘҝпјҢеүҚж–ҮдёӯиҜҙзҡ„жҳҜIndex AccessпјҢиҖҢиҝҷйҮҢжҳҜQuery OptimizationпјҢжүҖд»Ҙ并дёҚжһ„жҲҗеҜ№еүҚж–ҮжӯЈзЎ®жҖ§зҡ„еҪұе“ҚгҖӮеңЁеҶҷеүҚж–Үж—¶пјҢMySQLиҝҳжІЎжңүICPпјҢжүҖд»Ҙж–ҮдёӯжІЎжңүж¶үеҸҠзӣёе…іеҶ…е®№пјҢдҪҶиҖғиҷ‘еҲ°ж–°зүҲжң¬зҡ„MariaDBжҲ–MySQLдёӯICPзҡ„еҗҜз”ЁзЎ®е®һеҪұе“ҚдәҶдёҖдәӣжҹҘиҜўиЎҢдёәзҡ„еӨ–еңЁиЎЁзҺ°гҖӮжүҖд»ҘеҶіе®ҡеҶҷиҝҷзҜҮж–Үз« иҜҰз»Ҷи®Іиҝ°дёҖдёӢICPзҡ„еҺҹзҗҶд»ҘеҸҠеҜ№зҙўеј•дҪҝз”Ёж–№ејҸзҡ„дјҳеҢ–гҖӮ
е®һйӘҢ
е…Ҳд»ҺдёҖдёӘз®ҖеҚ•зҡ„е®һйӘҢејҖе§Ӣзӣҙи§Ӯи®ӨиҜҶICPзҡ„дҪңз”ЁгҖӮ
е®үиЈ…ж•°жҚ®еә“
йҰ–е…ҲйңҖиҰҒе®үиЈ…дёҖдёӘж”ҜжҢҒICPзҡ„MariaDBжҲ–MySQLж•°жҚ®еә“гҖӮжҲ‘дҪҝз”Ёзҡ„жҳҜMariaDB 5.5.34пјҢеҰӮжһңжҳҜдҪҝз”ЁMySQLеҲҷйңҖиҰҒ5.6зүҲжң¬д»ҘдёҠгҖӮ
MacзҺҜеўғдёӢеҸҜд»ҘйҖҡиҝҮbrewе®үиЈ…пјҡ
brew install mairadb
е…¶е®ғзҺҜеўғдёӢзҡ„е®үиЈ…иҜ·еҸӮиҖғMariaDBе®ҳзҪ‘е…ідәҺдёӢиҪҪе®үиЈ…зҡ„ж–ҮжЎЈгҖӮ
еҜје…ҘзӨәдҫӢж•°жҚ®
дёҺеүҚж–ҮдёҖж ·пјҢжҲ‘们дҪҝз”ЁEmployees Sample DatabaseпјҢдҪңдёәзӨәдҫӢж•°жҚ®еә“гҖӮе®Ңж•ҙзӨәдҫӢж•°жҚ®еә“зҡ„дёӢиҪҪең°еқҖдёәпјҡhttps://launchpad.net/test-db/employees-db-1/1.0.6/+download/employees_db-full-1.0.6.tar.bz2гҖӮ
е°ҶдёӢиҪҪзҡ„еҺӢзј©еҢ…и§ЈеҺӢеҗҺпјҢдјҡзңӢеҲ°дёҖзі»еҲ—зҡ„ж–Ү件пјҢе…¶дёӯemployees.sqlе°ұжҳҜеҜје…Ҙж•°жҚ®зҡ„е‘Ҫд»Өж–Ү件гҖӮжү§иЎҢ
mysql -h[host]-u[user]-p < employees.sql
е°ұеҸҜд»Ҙе®ҢжҲҗе»әеә“гҖҒе»әиЎЁе’Ңloadж•°жҚ®зӯүдёҖзі»еҲ—ж“ҚдҪңгҖӮжӯӨж—¶ж•°жҚ®еә“дёӯдјҡеӨҡдёҖдёӘеҸ«еҒҡemployeesзҡ„ж•°жҚ®еә“гҖӮеә“дёӯзҡ„иЎЁеҰӮдёӢпјҡ
MariaDB[employees]> SHOW TABLES;
+---------------------+
|Tables_in_employees|
+---------------------+
| departments |
| dept_emp |
| dept_manager |
| employees |
| salaries |
| titles |
+---------------------+
6 rows inset(0.00 sec)
жҲ‘们е°ҶдҪҝз”ЁemployeesиЎЁеҒҡе®һйӘҢгҖӮ
е»әз«ӢиҒ”еҗҲзҙўеј•
employeesиЎЁеҢ…еҗ«йӣҮе‘ҳзҡ„еҹәжң¬дҝЎжҒҜпјҢиЎЁз»“жһ„еҰӮдёӢпјҡ
MariaDB[employees]> DESC employees.employees;
+------------+---------------+------+-----+---------+-------+
|Field|Type|Null|Key|Default|Extra|
+------------+---------------+------+-----+---------+-------+
| emp_no |int(11)| NO | PRI | NULL ||
| birth_date | date | NO || NULL ||
| first_name | varchar(14)| NO || NULL ||
| last_name | varchar(16)| NO || NULL ||
| gender |enum('M','F')| NO || NULL ||
| hire_date | date | NO || NULL ||
+------------+---------------+------+-----+---------+-------+
6 rows inset(0.01 sec)
иҝҷдёӘиЎЁй»ҳи®ӨеҸӘжңүдёҖдёӘдё»зҙўеј•пјҢеӣ дёәICPеҸӘиғҪдҪңз”ЁдәҺдәҢзә§зҙўеј•пјҢжүҖд»ҘжҲ‘们е»әз«ӢдёҖдёӘдәҢзә§зҙўеј•пјҡ
ALTER TABLE employees.employees ADD INDEX first_name_last_name (first_name, last_name);
иҝҷж ·е°ұе»әз«ӢдәҶдёҖдёӘfirst_nameе’Ңlast_nameзҡ„иҒ”еҗҲзҙўеј•гҖӮ
жҹҘиҜў
дёәдәҶжҳҺзЎ®зңӢеҲ°жҹҘиҜўжҖ§иғҪпјҢжҲ‘们еҗҜз”Ёprofiling并关й—ӯquery cacheпјҡ
SET profiling =1;
SET query_cache_type =0;
SET GLOBAL query_cache_size =0;
然еҗҺжҲ‘们зңӢдёӢйқўиҝҷдёӘжҹҘиҜўпјҡ
MariaDB[employees]> SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+
|254642|1959-01-17|Mary|Botman| M |1989-11-24|
|471495|1960-09-24|Mary|Dymetman| M |1988-06-09|
|211941|1962-08-11|Mary|Hofman| M |1993-12-30|
|217707|1962-09-05|Mary|Lichtman| F |1987-11-20|
|486361|1957-10-15|Mary|Oberman| M |1988-09-06|
|457469|1959-07-15|Mary|Weedman| M |1996-11-21|
+--------+------------+------------+-----------+--------+------------+
ж №жҚ®MySQLзҙўеј•зҡ„еүҚзјҖеҢ№й…ҚеҺҹеҲҷпјҢдёӨиҖ…еҜ№зҙўеј•зҡ„дҪҝз”ЁжҳҜдёҖиҮҙзҡ„пјҢеҚіеҸӘжңүfirst_nameйҮҮз”Ёзҙўеј•пјҢlast_nameз”ұдәҺдҪҝз”ЁдәҶжЁЎзіҠеүҚзјҖпјҢжІЎжі•дҪҝз”Ёзҙўеј•иҝӣиЎҢеҢ№й…ҚгҖӮжҲ‘е°ҶжҹҘиҜўиҒ”зі»жү§иЎҢдёүж¬ЎпјҢз»“жһңеҰӮдёӢпјҡ
+----------+------------+---------------------------------------------------------------------------+
|Query_ID|Duration|Query|
+----------+------------+---------------------------------------------------------------------------+
|38|0.00084400| SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man'|
|39|0.00071800| SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man'|
|40|0.00089600| SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man'|
+----------+------------+---------------------------------------------------------------------------+
然еҗҺжҲ‘们关й—ӯICPпјҡ
SET optimizer_switch='index_condition_pushdown=off';
еңЁиҝҗиЎҢдёүж¬ЎзӣёеҗҢзҡ„жҹҘиҜўпјҢз»“жһңеҰӮдёӢпјҡ
+----------+------------+---------------------------------------------------------------------------+
|Query_ID|Duration|Query|
+----------+------------+---------------------------------------------------------------------------+
|42|0.00264400| SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man'|
|43|0.01418900| SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man'|
|44|0.00234200| SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man'|
+----------+------------+---------------------------------------------------------------------------+
жңүж„ҸжҖқзҡ„дәӢжғ…еҸ‘з”ҹдәҶпјҢе…ій—ӯICPеҗҺпјҢеҗҢж ·зҡ„жҹҘиҜўпјҢиҖ—ж—¶жҳҜд№ӢеүҚзҡ„дёүеҖҚд»ҘдёҠгҖӮдёӢйқўжҲ‘们用explainзңӢзңӢдёӨиҖ…жңүд»Җд№ҲеҢәеҲ«пјҡ
MariaDB[employees]> EXPLAIN SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
+------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len |ref| rows |Extra|
+------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
|1| SIMPLE | employees |ref| first_name_last_name | first_name_last_name |44|const|224|Using index condition |
+------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-----------------------+
1 row inset(0.00 sec)
MariaDB[employees]> EXPLAIN SELECT * FROM employees WHERE first_name='Mary' AND last_name LIKE '%man';
+------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len |ref| rows |Extra|
+------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
|1| SIMPLE | employees |ref| first_name_last_name | first_name_last_name |44|const|224|Usingwhere|
+------+-------------+-----------+------+----------------------+----------------------+---------+-------+------+-------------+
1 row inset(0.00 sec)
еүҚиҖ…жҳҜејҖеҗҜICPпјҢеҗҺиҖ…жҳҜе…ій—ӯICPгҖӮеҸҜд»ҘзңӢеҲ°еҢәеҲ«еңЁдәҺExtraпјҢејҖеҗҜICPж—¶пјҢз”Ёзҡ„жҳҜUsing index conditionпјӣе…ій—ӯICPж—¶пјҢжҳҜUsing whereгҖӮ
е…¶дёӯUsing index conditionе°ұжҳҜICPжҸҗй«ҳжҹҘиҜўжҖ§иғҪзҡ„е…ій”®гҖӮдёӢдёҖиҠӮиҜҙжҳҺICPжҸҗй«ҳжҹҘиҜўжҖ§иғҪзҡ„еҺҹзҗҶгҖӮ
еҺҹзҗҶ
ICPзҡ„еҺҹзҗҶз®ҖеҚ•иҜҙжқҘе°ұжҳҜе°ҶеҸҜд»ҘеҲ©з”Ёзҙўеј•зӯӣйҖүзҡ„whereжқЎд»¶еңЁеӯҳеӮЁеј•ж“ҺдёҖдҫ§иҝӣиЎҢзӯӣйҖүпјҢиҖҢдёҚжҳҜе°ҶжүҖжңүindex accessзҡ„з»“жһңеҸ–еҮәж”ҫеңЁserverз«ҜиҝӣиЎҢwhereзӯӣйҖүгҖӮ
д»ҘдёҠйқўзҡ„жҹҘиҜўдёәдҫӢпјҢеңЁжІЎжңүICPж—¶пјҢйҰ–е…ҲйҖҡиҝҮзҙўеј•еүҚзјҖд»ҺеӯҳеӮЁеј•ж“ҺдёӯиҜ»еҮә224жқЎfirst_nameдёәMaryзҡ„и®°еҪ•пјҢ然еҗҺеңЁserverж®өз”ЁwhereзӯӣйҖүlast_nameзҡ„likeжқЎд»¶пјӣиҖҢеҗҜз”ЁICPеҗҺпјҢз”ұдәҺlast_nameзҡ„likeзӯӣйҖүеҸҜд»ҘйҖҡиҝҮзҙўеј•еӯ—ж®өиҝӣиЎҢпјҢйӮЈд№ҲеӯҳеӮЁеј•ж“ҺеҶ…йғЁйҖҡиҝҮзҙўеј•дёҺwhereжқЎд»¶зҡ„еҜ№жҜ”жқҘзӯӣйҖүжҺүдёҚз¬ҰеҗҲwhereжқЎд»¶зҡ„и®°еҪ•пјҢиҝҷдёӘиҝҮзЁӢдёҚйңҖиҰҒиҜ»еҮәж•ҙжқЎи®°еҪ•пјҢеҗҢж—¶еҸӘиҝ”еӣһз»ҷserverзӯӣйҖүеҗҺзҡ„6жқЎи®°еҪ•пјҢеӣ жӯӨжҸҗй«ҳдәҶжҹҘиҜўжҖ§иғҪгҖӮ
дёӢйқўйҖҡиҝҮеӣҫдёӨз§ҚжҹҘиҜўзҡ„еҺҹзҗҶиҜҰз»Ҷи§ЈйҮҠгҖӮ
е…ій—ӯICP
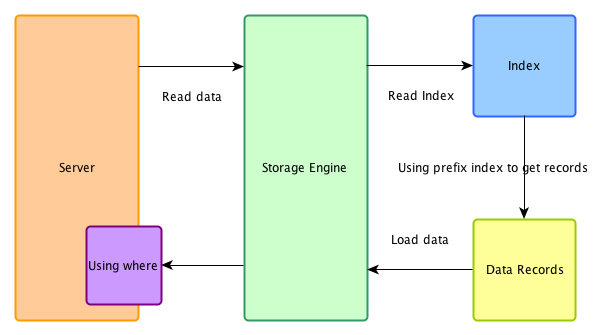
еңЁдёҚж”ҜжҢҒICPзҡ„зі»з»ҹдёӢпјҢзҙўеј•д»…д»…дҪңдёәdata accessдҪҝз”ЁгҖӮ
ејҖеҗҜICP
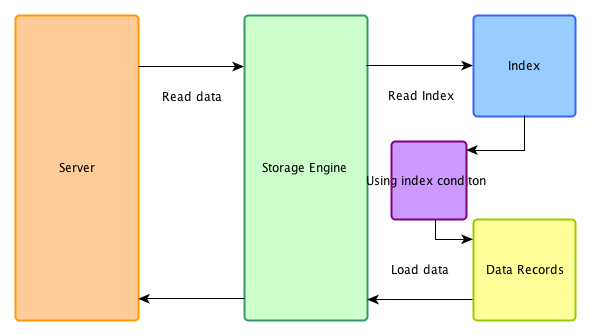
еңЁICPдјҳеҢ–ејҖеҗҜж—¶пјҢеңЁеӯҳеӮЁеј•ж“Һз«ҜйҰ–е…Ҳз”Ёзҙўеј•иҝҮж»ӨеҸҜд»ҘиҝҮж»Өзҡ„whereжқЎд»¶пјҢ然еҗҺеҶҚз”Ёзҙўеј•еҒҡdata accessпјҢиў«index conditionиҝҮж»ӨжҺүзҡ„ж•°жҚ®дёҚеҝ…иҜ»еҸ–пјҢд№ҹдёҚдјҡиҝ”еӣһserverз«ҜгҖӮ
жіЁж„ҸдәӢйЎ№
жңүеҮ дёӘе…ідәҺICPзҡ„дәӢжғ…иҰҒжіЁж„Ҹпјҡ
-
ICPеҸӘиғҪз”ЁдәҺдәҢзә§зҙўеј•пјҢдёҚиғҪз”ЁдәҺдё»зҙўеј•гҖӮ
-
д№ҹдёҚжҳҜе…ЁйғЁwhereжқЎд»¶йғҪеҸҜд»Ҙз”ЁICPзӯӣйҖүпјҢеҰӮжһңжҹҗwhereжқЎд»¶зҡ„еӯ—ж®өдёҚеңЁзҙўеј•дёӯпјҢеҪ“然иҝҳжҳҜиҰҒиҜ»еҸ–ж•ҙжқЎи®°еҪ•еҒҡзӯӣйҖүпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢд»Қ然иҰҒеҲ°serverз«ҜеҒҡwhereзӯӣйҖүгҖӮ
-
ICPзҡ„еҠ йҖҹж•ҲжһңеҸ–еҶідәҺеңЁеӯҳеӮЁеј•ж“ҺеҶ…йҖҡиҝҮICPзӯӣйҖүжҺүзҡ„ж•°жҚ®зҡ„жҜ”дҫӢгҖӮ
еҸӮиҖғ
[1] https://mariadb.com/kb/en/index-condition-pushdown/
[2] http://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html