тЅЇУеђ
т»╣С║јСИђСИфwebуйЉуФЎуџёТђДУЃйТЮЦУ»┤№╝їуЊХжбѕтцџтЇіТў»ТЮЦУЄфС║јТЋ░ТЇ«т║ЊсђѓСИђУѕгТЋ░ТЇ«т║ЊТЪЦУ»бС╝џтюеТЪљСИфУ»иТ▒ѓуџёТЋ┤СйЊУђЌТЌХСИГтЇатЙѕтцДТ»ћСЙІсђѓтдѓТъюУЃйТЈљжФўТЋ░ТЇ«т║ЊТЪЦУ»буџёТЋѕујЄ№╝їуйЉуФЎуџёТЋ┤СйЊтЊЇт║ћТЌХжЌ┤С╝џТюЅтЙѕтцДуџёСИІжЎЇсђѓтдѓТъюУЃйт«ъуј░mysqlТЪЦУ»буџёт╝ѓТГЦтїќ№╝їт░▒тЈ»С╗Цт«ъуј░тцџТЮАsqlУ»ГтЈЦтљїТЌХТЅДУАїсђѓУ┐ЎТаит░▒тЈ»С╗ЦтцДтцДу╝ЕуЪГmysqlТЪЦУ»буџёУђЌТЌХсђѓ
т╝ѓТГЦСИ║тЋЦТ»ћтљїТГЦт┐Ф№╝Ъ
СИјт╝ѓТГЦТЪЦУ»буЏИтЈЇуџёТЌХтљїТГЦТЪЦУ»бсђѓжђџтИИТЃЁтєхСИІmysqlуџёqueryТЪЦУ»бжЃйТў»тљїТГЦТќ╣т╝ЈсђѓСИІжЮбТѕЉС╗гт»╣СИцуДЇТќ╣т╝ЈтЂџСИІт»╣Т»ћсђѓт»╣Т»ћуџёСЙІтГљТў»№╝їУ»иТ▒ѓСИцТгАselect sleep(1)сђѓУ┐ЎТЮАУ»ГтЈЦтюеmysqlТюЇтіАтЎеуФ»тцДТдѓУђЌТЌХ1000msсђѓ
тљїТГЦТќ╣т╝ЈуџёТЅДУАїТхЂуеІ№╝џ
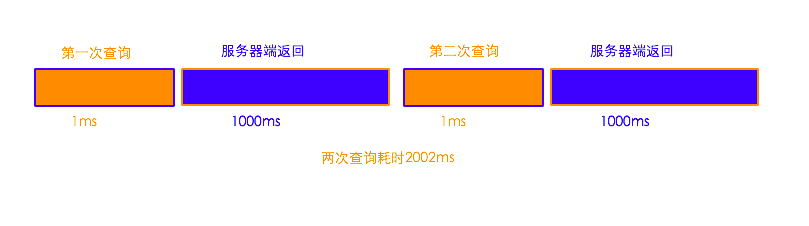
уггСИђТГЦ№╝їтљЉmysqlТюЇтіАтЎеуФ»тЈЉжђЂуггСИђТгАТЪЦУ»бУ»иТ▒ѓсђѓтцДТдѓУђЌТЌХ 1ms
уггС║їТГЦ№╝їmysqlТюЇтіАтЎеуФ»У┐ћтЏъуггСИђТгАТЪЦУ»буџёу╗ЊТъюсђѓтцДТдѓУђЌТЌХ 1000ms
уггСИЅТГЦ№╝їтљЉmysqlТюЇтіАтЎетєЇТгАтЈЉжђЂУ»иТ▒ѓсђѓтцДТдѓУђЌТЌХ 1ms
уггтЏЏТГЦ№╝їmysqlТюЇтіАтЎеуФ»У┐ћтЏъуггС║їТгАТЪЦУ»буџёу╗ЊТъюсђѓтцДТдѓУђЌТЌХ 1000ms
тљїТГЦуџёТќ╣т╝ЈТЅДУАїСИцТгАselect sleep(1)№╝їтцДТдѓУђЌТЌХ 2002msсђѓ
т╝ѓТГЦТќ╣т╝ЈуџёТЅДУАїТхЂуеІ№╝џ
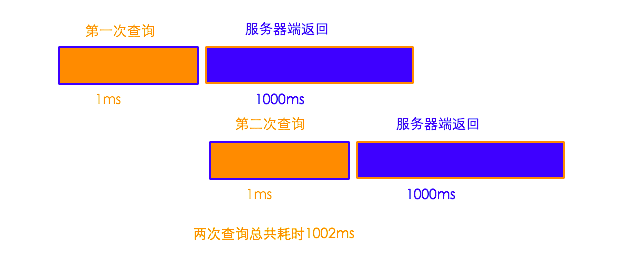
уггСИђТГЦ№╝їтљЉmysqlТюЇтіАтЎеуФ»тЈЉжђЂуггСИђТгАТЪЦУ»бУ»иТ▒ѓсђѓтцДТдѓУђЌТЌХ1ms
уггС║їТГЦ№╝їтюеуГЅтЙЁуггСИђТгАУ»иТ▒ѓУ┐ћтЏъТЋ░ТЇ«уџётљїТЌХ№╝їтљЉТюЇтіАтЎеуФ»тЈЉжђЂуггС║їТгАТЪЦУ»бУ»иТ▒ѓсђѓтцДТдѓУђЌТЌХ 1ms
уггСИЅТГЦ№╝їТјЦтЈЌmysqlТюЇтіАтЎеуФ»У┐ћтЏъуџёСИцТгАТЪЦУ»бУ»иТ▒ѓсђѓтцДТдѓУђЌТЌХ 1000msсђѓ
т»╣Т»ћтѕєТъљ
т╝ѓТГЦТЪЦУ»бТ»ћтљїТГЦТЪЦУ»бжђЪт║дт┐Ф№╝їТў»тЏаСИ║тцџТЮАТЪЦУ»бУ»ГтЈЦтюеТюЇтіАтЎеуФ»тљїТЌХТЅДУАї№╝їтцДтцДу╝ЕуЪГС║єТюЇтіАтЎеуФ»уџётЊЇт║ћТЌХжЌ┤сђѓт╣ХУАїСИђУѕгТЃЁтєхСИІТђ╗Т»ћСИ▓УАїт┐ФтўЏсђѓsqlУ»ГтЈЦТЅДУАїТЌХжЌ┤УХіжЋ┐№╝їТЋѕТъюУХіТўјТўЙсђѓ
тдѓСйЋт«ъуј░mysqlуџёт╝ѓТГЦТЪЦУ»б№╝Ъ
УдЂт«ъуј░т╝ѓТГЦТЪЦУ»буџётЁ│жћ«Тў»УЃйТіітЈЉжђЂУ»иТ▒ѓтњїТјЦтЈЌУ┐ћтЏъТЋ░ТЇ«тѕєт╝ђсђѓТГБтЦйmysqlndСИГТЈљСЙЏС║єУ┐ЎСИфуЅ╣ТђДсђѓ
тюеmysqlndСИГт»╣т║ћуџёТќ╣Т│ЋТў»№╝џ
mysqlnd_async_query тЈЉжђЂТЪЦУ»бУ»иТ▒ѓ
mysqlnd_reap_async_query УјитЈќТЪЦУ»бу╗ЊТъю
mysqliТЅЕт▒Ћжњѕт»╣mysqlndуџёУ┐ЎСИфуЅ╣ТђДтЂџС║єт░ЂУБЁ№╝їтюеУ░ЃућеqueryТќ╣Т│ЋТЌХ№╝їС╝атЁЦMYSQLI_ASYNCтЇ│тЈ»сђѓ
тЁиСйЊС╗БуаЂт«ъуј░тЈ»С╗ЦТЪЦуюІтЇџТќЄ phpСИГmysqlТЋ░ТЇ«т║Њт╝ѓТГЦТЪЦУ»бт«ъуј░
СИ║тЋЦСй┐ућетЇЈуеІ№╝Ъ
ТЪЦуюІС║єтЇџТќЄСИГуџёС╗БуаЂт«ъуј░№╝їТў»СИЇТў»ТёЪУДЅтєЎТ│Ћтњїт╣│ТЌХСИЇСИђТаи№╝ЪСИђУѕгтюежА╣уЏ«тйЊСИГ№╝їТѕЉС╗гжЃйТў»С╗Цfunctionуџётйбт╝Јтј╗уЏИС║њУ░Ѓуће№╝їfunctionСИГтїЁтљФС║єТЋ░ТЇ«т║ЊТЪЦУ»бсђѓСИ║С║єС┐ЮТїЂУ┐ЎСИфС╣аТЃ»№╝їТќ╣СЙ┐тцДт«ХСй┐уће№╝їтЏаТГцт╝ЋтЁЦС║єтЇЈуеІсђѓтюеphp5.5СИГТГБтЦйТЈљСЙЏС║єyieldтњїgenerator№╝їТќ╣СЙ┐ТѕЉС╗гт«ъуј░тЇЈуеІсђѓуц║СЙІС╗БуаЂтдѓСИІ№╝џ
<?php
function f1(){
$db = new db();
$obj = $db->async_query('select sleep(1)');
echo "f1 async_query \n";
yield $obj;
$row = $db->fetch();
echo "f1 fetch\n";
yield $row;
}
function f2(){
$db = new db();
$obj = $db->async_query('select sleep(1)');
echo "f2 async_query\n";
yield $obj;
$row = $db->fetch();
echo "f2 fetch\n";
yield $row;
}
$gen1 = f1();
$gen2 = f2();
$gen1->current();
$gen2->current();
$gen1->next();
$gen2->next();
$ret1 = $gen1->current();
$ret2 = $gen2->current();
var_dump($ret1);
var_dump($ret2);
class db{
static $links;
private $obj;
function getConn(){
$host = '127.0.0.1';
$user = 'demo';
$password = 'demo';
$database = 'demo';
$this->obj = new mysqli($host, $user, $password, $database);
self::$links[spl_object_hash($this->obj)] = $this->obj;
return self::$links[spl_object_hash($this->obj)];
}
function async_query($sql){
$link = $this->getConn();
$link->query($sql, MYSQLI_ASYNC);
return $link;
}
function fetch(){
for($i = 1; $i <= 5; $i++){
$read = $errors = $reject = self::$links;
$re = mysqli_poll($read, $errors, $reject, 1);
foreach($read as $obj){
if($this->obj === $obj){
$sql_result = $obj->reap_async_query();
$sql_result_array = $sql_result->fetch_array(MYSQLI_ASSOC);//тЈфТюЅСИђУАї
$sql_result->free();
return $sql_result_array;
}
}
}
}
}
?>
тюеу╗ѕуФ»тЉйС╗цУАїТќ╣т╝ЈТЅДУАїу╗ЊТъютдѓСИІ№╝џ
$time php ./async.php
f1 async_query
f2 async_query
f1 fetch
f2 fetch
array(1) {
["sleep(1)"]=>
string(1) "0"
}
array(1) {
["sleep(1)"]=>
string(1) "0"
}
real 0m1.016s
user 0m0.007s
С╗ју╗ЊТъюСИіТѕЉС╗гтЈ»С╗ЦуюІтЄ║ТЅДУАїТхЂуеІТў»№╝їтЁѕтЈЉС║єСИцТгАmysqlТЪЦУ»б№╝їуёХтљјтюеТјЦтЈЌТЋ░ТЇ«т║ЊуџёУ┐ћтЏъТЋ░ТЇ«сђѓТГБтИИТЃЁтєхСИІ№╝їУЄ│т░ЉжюђУдЂ2000msТЅЇУЃйТЅДУАїт«їТ»ЋсђѓСйєТў»№╝їreal 0m1.016s№╝їУ»┤ТўјСИцТгАТЪЦУ»буџёУђЌТЌХтЈфТюЅ1016msсђѓ
tips№╝џС╗ЦСИіС╗БуаЂтЈфТў»уц║СЙІС╗БуаЂ№╝їУ┐ўТюЅСИђС║ЏжюђУдЂт«їтќёуџётю░Тќ╣сђѓ
Т│еТёЈ
жюђУдЂТ│еТёЈуџёТў»№╝їтдѓТъюmysqlТюЇтіАтЎеТюгУ║ФУ┤ЪУййтЙѕтцД№╝їУ┐ЎуДЇт╣ХУАїТЅДУАїуџёТќ╣т╝Јт░▒СИЇСИђт«џТў»тЦйуџёУДБтє│Тќ╣Т│ЋсђѓтЏаСИ║№╝їmysqlТюЇтіАуФ»С╝џСИ║Т»ЈСИфжЊЙТјЦтѕЏт╗║СИђСИфтЇЋуІгуџёу║┐уеІУ┐ЏУАїтцёуљєсђѓтдѓТъютѕЏт╗║уџёу║┐уеІТЋ░У┐Єтцџ№╝їС╝џу╗Ўу│╗у╗ЪжђаТѕљУ┤ЪТІЁсђѓ
тЈѓУђЃУхёТќЎ
Asynchronous MySQL How Facebook Queries Databases