жҖ»дҪ“жқҘиҜҙпјҢдјҳеҢ–зҡ„еҺҹеҲҷе’ҢеҜ№еҚ•зӢ¬зҡ„иЎЁеҒҡдјҳеҢ–жҳҜдёҖж ·зҡ„пјҢдҝқиҜҒеҜ№зЈҒзӣҳдёҠиЎЁзҡ„жү«жҸҸж¬Ўж•°еҮҸе°ҸгҖӮ
жҲ‘们зҡ„иЎЁз»“жһ„еҰӮдёӢпјҡ
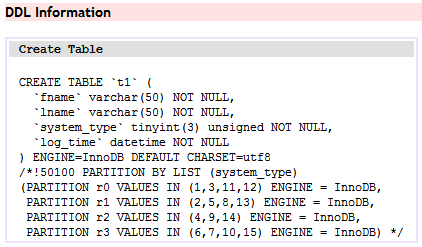
иҝҷйҮҢе·Із»ҸжҸ’е…Ҙ2WеӨҡиЎҢж•°жҚ®иҝӣиЎҢжөӢиҜ•гҖӮ
зңӢзңӢиҝҷжқЎжҹҘиҜўгҖӮ
SELECT * FROM t1 WHERE system_type IN (1,2)
UNION ALL
SELECT * FROM t1 WHERE system_type = 3;
иҝҷжқЎиҜӯеҸҘеҜ№system_typeеӯ—ж®өиҝҮж»ӨдәҶдёӨж¬ЎпјҢ然еҗҺиҝӣиЎҢдәҶдёҖж¬ЎUNION ALLгҖӮ дҪҶжҳҜдёҚзҹҘйҒ“пјҢе…¶е®һеҜ№дёӨдёӘеҲҶеҢәдёҖе…ұиҝӣиЎҢдәҶдёүж¬Ўе…ЁиЎЁжү«жҸҸгҖӮ
жҲ‘们改жҲҗиҝҷж ·пјҡ
SELECT * FROM t1 WHERE system_type IN (1,3)
UNION ALL
SELECT * FROM t1 WHERE system_type = 2;
зңӢдјјз®Җз®ҖеҚ•еҚ•зҡ„ж”№еҸҳпјҢжҲ‘们жҠҠеҜ№дёӨдёӘеҲҶеҢәзҡ„жү«жҸҸд»Һдёүж¬ЎеҮҸе°‘еҲ°дәҶдёӨж¬ЎгҖӮ дҪҶжҳҜиҝҷж ·пјҢејҖй”Җд№ҹеҫҲеӨ§пјҢиғҪдёҚиғҪжҠҠUNION ALLеҺ»жҺүе‘ўпјҹеҪ“然еҸҜд»ҘгҖӮ
SELECT * FROM t1 WHERE system_type >0 and system_type < 4;
еҺ»жҺүдәҶUNION ALLпјҢдҪҶжҳҜйҒҮеҲ°зҡ„й—®йўҳжҳҜеҜ№еҲҶеҢәзҡ„жү«жҸҸеҸҳжҲҗдәҶиҢғеӣҙжҹҘжүҫпјҢиҖҢдё”дёҠдёӢйҷҗдёҚеӣәе®ҡпјҢзӣёеҜ№жқҘиҜҙпјҢиҝҳжңүдјҳеҢ–зҡ„з©әй—ҙгҖӮ
жҲ‘们改дёӢеҜ№system_typeеҲ—зҡ„иҝҮж»ӨжқЎд»¶пјҢеҸҳжҲҗеҰӮдёӢпјҡ
SELECT * FROM t1 WHERE system_type in(1,2,3);
idselect_typetablepartitionstypepossible_keyskeykey_lenrefrowsExtra
1SIMPLEt1r0,r1ALL\N\N\N\N17719Using where
зҺ°еңЁпјҢдҫқ然жҳҜиҢғеӣҙжү«жҸҸпјҢдҪҶжҳҜдёҠдёӢйҷҗе°ұеҫҲжҳҺдәҶдәҶгҖӮиҝҷж ·еҜ№жү«жҸҸеҲҶеҢәжқҘиҜҙпјҢеҫҲеҝ«зҡ„жүҫеҲ°дёҠдёӢйҷҗпјҢжҜ”д№ӢеүҚжқҘзҡ„иҰҒеҝ«пјҢејҖй”ҖжқҘзҡ„иҰҒе°ҸзӮ№дәҶгҖӮ
дҪҶжҳҜиІҢдјјиҝҳеҸҜд»ҘдјҳеҢ–пјҢ иҷҪ然иҝҮж»ӨжқЎд»¶зҡ„дёҠдёӢйҷҗжҳҺжҳҫдәҶпјҢдҪҶжҳҜеҜ№дәҺеҢәеҹҹд№ӢеҶ…зҡ„жү«жҸҸиҝҳжҳҜе…ЁеҲҶеҢәпјҲзӣёеҪ“дәҺж•ҙдёӘиЎЁзҡ„е…ЁиЎЁгҖӮпјүгҖӮ
OKпјҢйӮЈзҺ°еңЁз»ҷиҝҷдёӘеҲ—еҠ дёҠзҙўеј•еҗ§гҖӮ
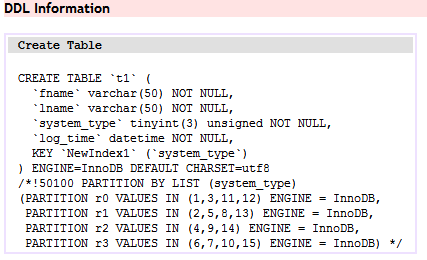
ALTER TABLE t1 ANALYZE PARTITION r0,r1;
SELECT * FROM t1 WHERE system_type in(1,2,3);
idselect_typetablepartitionstypepossible_keyskeykey_lenrefrowsExtra
1SIMPLEt1r0,r1rangeNewIndex1NewIndex11\N6462Using where
еҪ“然пјҢжҲ‘们зҡ„дҫӢеӯҗйқһеёёз®ҖеҚ•пјҢ иҝҷйҮҢеҸӘжҳҜдёәдәҶжј”зӨәдёӢеңЁж°ҙе№іеҲҶеҢәдёӢеҰӮдҪ•иҝӣиЎҢSQLдјҳеҢ–гҖӮ